Skip to main content
Search
Search This Blog
Rob on Programming
Posts
Showing posts from 2014
Show all
November 17, 2014
Autohotkey script to generate a BIRT report from Eclipse Report Design perspective
October 21, 2014
JUnit Parameterized and named tests
October 16, 2014
Script to pump output into a text file and open it in an editor
October 04, 2014
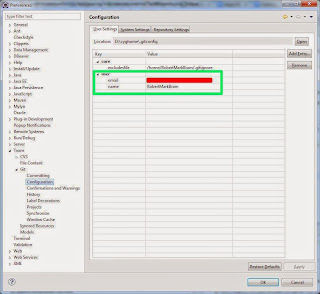
Add Eclipse Project to Local and Remote Git Repository
September 23, 2014
The installer is unable to instantiate the file KEY_XE.reg
September 23, 2014
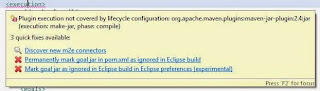
Plugin execution not covered by lifecycle configuration
September 15, 2014
Java process that can be stopped via sockets
September 08, 2014
Flip a coin and get the same results 100 times in a row
May 29, 2014
Regex to replace upper case with lower case in UltraEdit
March 22, 2014
Listary, Directory Opus and AutoHotkey - a match made in Geek Heaven
January 20, 2014
Testing synchronous vs asynchronous Dojo 1.9
Newer Posts
Older Posts
Home